1.错误发生在从hdfs下载csv文件到本地,利用pandas读取报错
出现此错误的原因是因为输入文件的路径是文件夹路径,而不是文件本身。
查看本地文件,果然data_rh.csv是个假数据文件打开里面有很多小文件。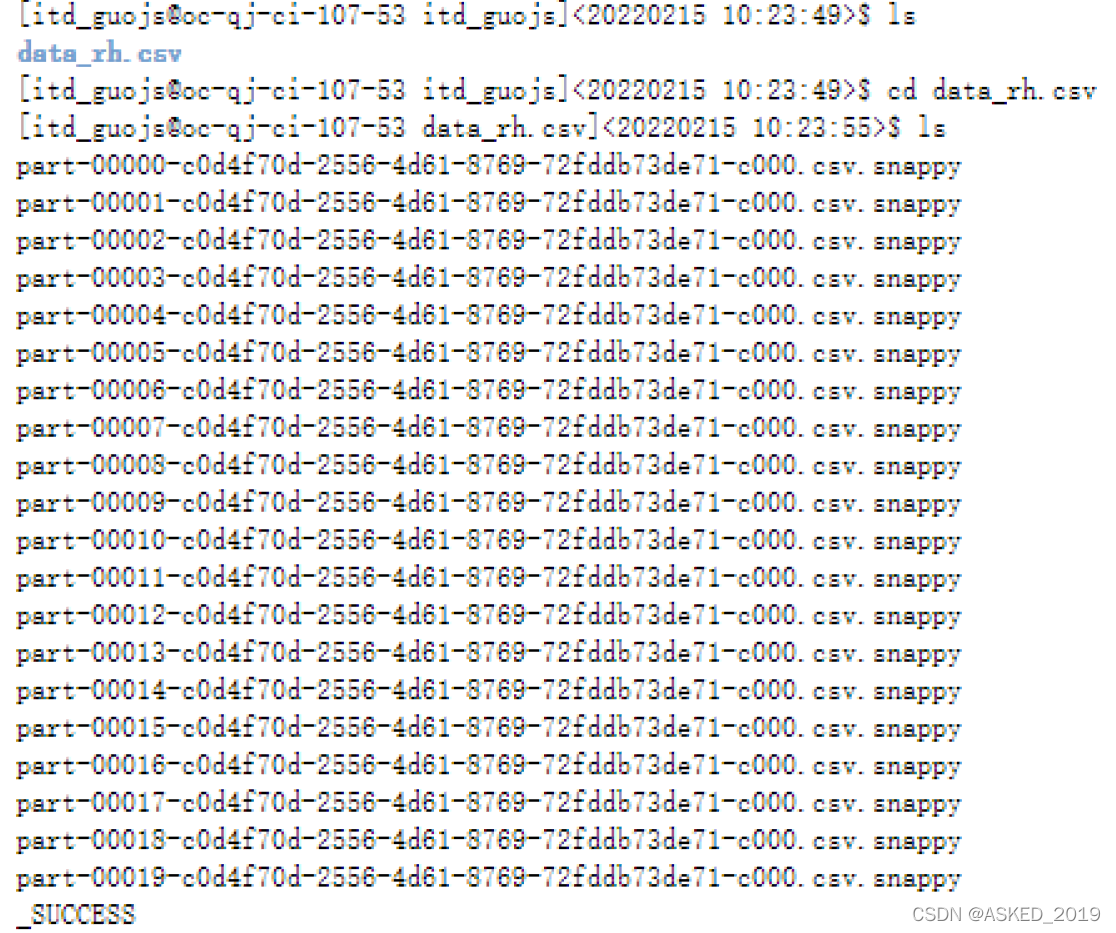
主要是利用spark df.write.format(“csv”).save("/tmp/myFile.csv") 保存的是一个myFile.csv的文件夹,有两个问题:
- hadoop fs -get 命令得到是一堆文件。
- 文件都是以snappy格式压缩的
第一个问题,可以使用coalesce进行合并,df.coalesce(1).write.option(“header”, “true”).csv(“myFile.csv”)
这样的写法同样会产生一个myFile.csv的文件夹,但其中的数据会全部保存到单个csv文件中
第二个问题,由于我使用的是sparkmagic,所以默认压缩是snappy, 可以在csv的compression参数进行设置。
df.coalesce(1)\ .write.option("header", "true")\ .csv(path="myFile.csv", compression="none")