前言
DStream上的原语与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
| Transformation | Meaning |
|---|---|
| map(func) | 将源DStream中的每个元素通过一个函数func从而得到新的DStreams。 |
| flatMap(func) | 和map类似,但是每个输入的项可以被映射为0或更多项。 |
| filter(func) | 选择源DStream中函数func判为true的记录作为新DStreams。 |
| repartition(numPartitions) | 通过创建更多或者更少的partition来改变此DStream的并行级别。 |
| union(otherStream) | 联合源DStreams和其他DStreams来得到新DStream。 |
| count() | 统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams。 |
| reduce(func) | 通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算。 |
| countByValue() | 对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率。 |
| reduceByKey(func, [numTasks]) | 对(K,V)对的DStream调用此函数,返回同样(K,V)对的新DStream,但是新DStream中的对应V为使用reduce函数整合而来。Note:默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。你也可以传入可选的参数numTaska来设置不同数量的任务。 |
| join(otherStream, [numTasks]) | 两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream。 |
| cogroup(otherStream, [numTasks]) | 两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams |
| transform(func) | 将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作。 |
| updateStateByKey(func) | 得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据。 |
DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
-
在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map()、filter()、reduceByKey() 等,都是无状态转化操作。
-
相对地,有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。
一、无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。 注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加import StreamingContext._ 才能在 Scala中使用。
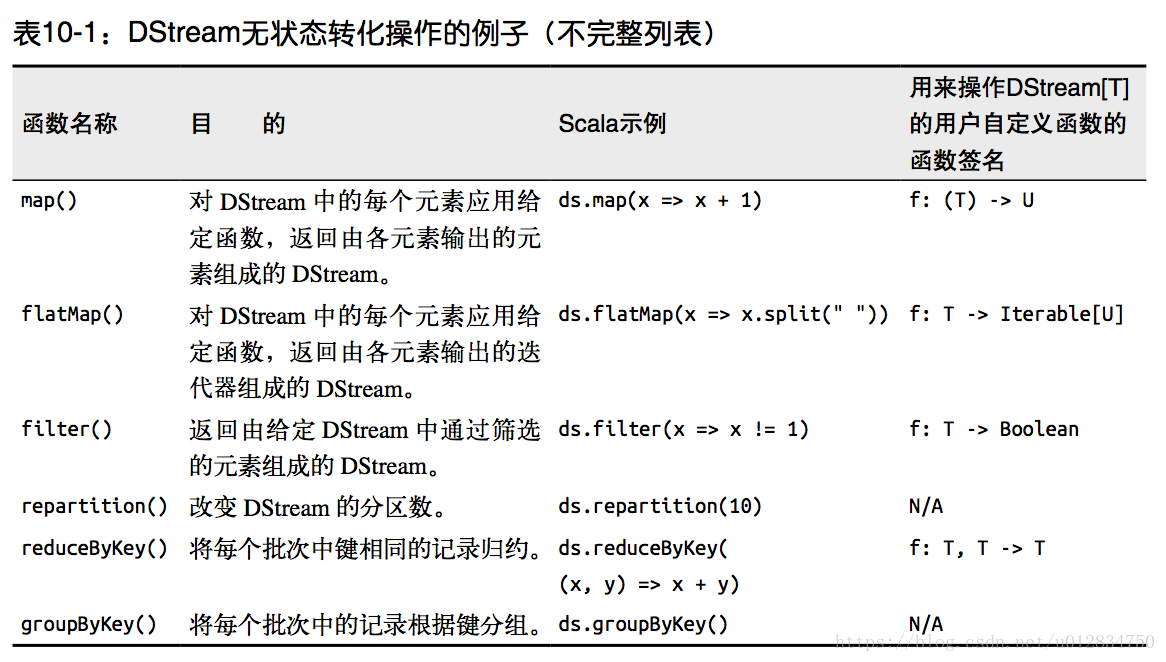
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如, reduceByKey() 会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
举个例子,在之前的wordcount程序中,我们只会统计1秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对 DStream 拥有和 RDD 一样的与连接相关的转化操作,也就是 cogroup()、join()、 leftOuterJoin() 等。我们可以在 DStream 上使用这些操作,这样就对每个批次分别执行了对应的 RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并多个流。
二、有状态转化操作
特殊的Transformations
2.1 追踪状态变化UpdateStateByKey
UpdateStateByKey原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件 更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,你需要做下面两步: 1. 定义状态,状态可以是一个任意的数据类型。 2. 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
objectWorldCount {def main(args: Array[String]) {// 需要创建一个SparkConfval conf =new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")// 需要创建一个StreamingContextval ssc =new StreamingContext(conf, Seconds(3))// 需要设置一个checkpoint的目录。 ssc.checkpoint(".")// 通过StreamingContext来获取hadoop0机器上9999端口传过来的语句val lines = ssc.socketTextStream("hadoop0",9999)// 需要通过空格将语句中的单词进行分割DStream[RDD[String]]val words = lines.flatMap(_.split(" "))//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3// 需要将每一个单词都映射成为一个元组(word,1)val pairs = words.map(word => (word,1))// 定义一个更新方法,values是当前批次RDD中相同key的value集合,state是框架提供的上次state的值val updateFunc = (values: Seq[Int], state: Option[Int]) => {// 计算当前批次相同key的单词总数val currentCount = values.foldLeft(0)(_ + _)// 获取上一次保存的单词总数val previousCount = state.getOrElse(0)// 返回新的单词总数 Some(currentCount + previousCount) }// 使用updateStateByKey方法,类型参数是状态的类型,后面传入一个更新方法。val stateDstream = pairs.updateStateByKey[Int](updateFunc)//输出 stateDstream.print() stateDstream.saveAsTextFiles("hdfs://hadoop0:9000/statful/","abc") ssc.start()// Start the computation ssc.awaitTermination()// Wait for the computation to terminate } }2.2 Window Operations
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
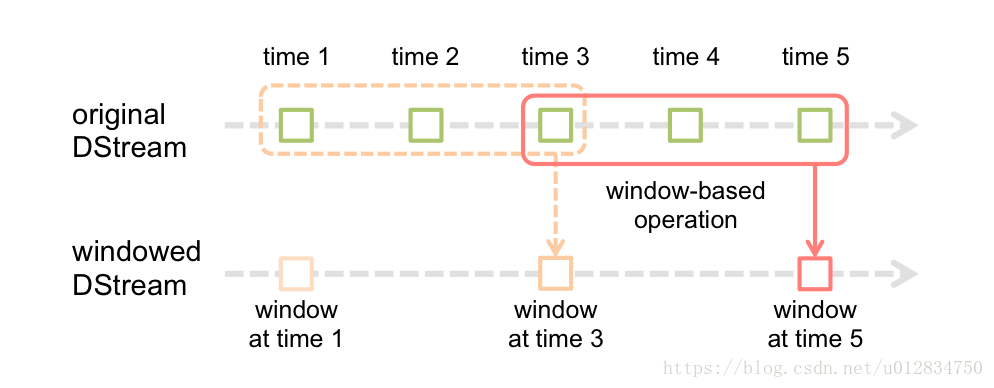
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作reduceByKeyAndWindow.
# reduce last 30 seconds of data, every 10 second windowedWordCounts = pairs.reduceByKeyAndWindow(lambda x, y: x + y,lambda x, y: x -y,30,20)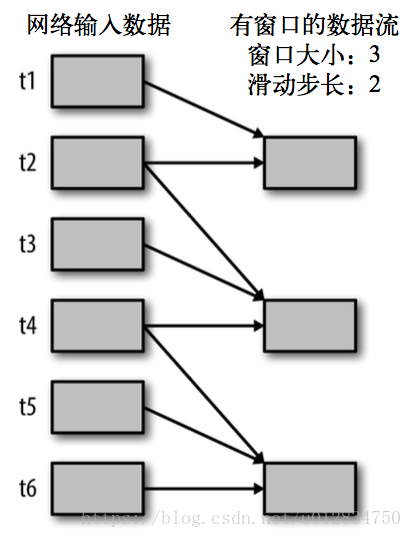
| Tables | Are |
|---|---|
| Transformation | Meaning |
| window(windowLength, slideInterval) | 基于对源DStream窗化的批次进行计算返回一个新的DStream |
| countByWindow(windowLength, slideInterval) | 返回一个滑动窗口计数流中的元素。 |
| reduceByWindow(func, windowLength, slideInterval) | 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。Note:默认情况下,这个操作使用Spark的默认数量并行任务(本地是2),在集群模式中依据配置属性(spark.default.parallelism)来做grouping。你可以通过设置可选参数numTasks来设置不同数量的tasks。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 这个函数是上述函数的更高效版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。注意:为了使用这个操作,检查点必须可用。 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的值是其在滑动窗口中频率。如上,可配置reduce任务数量。 |
reduceByWindow() 和 reduceByKeyAndWindow() 让我们可以对每个窗口更高效地进行归约操作。它们接收一个归约函数,在整个窗口上执行,比如 +。除此以外,它们还有一种特殊形式,通过只考虑新进入窗口的数据和离开窗 口的数据,让 Spark 增量计算归约结果。这种特殊形式需要提供归约函数的一个逆函数,比 如 + 对应的逆函数为 -。对于较大的窗口,提供逆函数可以大大提高执行效率。
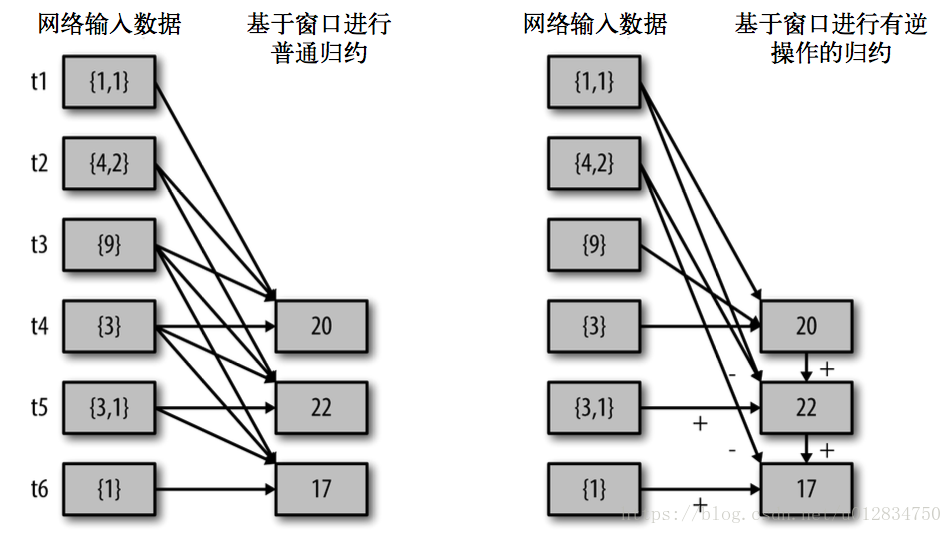
val ipDStream = accessLogsDStream.map( logEntry => (logEntry.getIpAddress(),1) )
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y},
{(x, y) => x - y},
Seconds(30),
Seconds(10)
)// 加上新进入窗口的批次中的元素// 移除离开窗口的老批次中的元素// 窗口时长// 滑动步长countByWindow() 和 countByValueAndWindow() 作为对数据进行 计数操作的简写。countByWindow() 返回一个表示每个窗口中元素个数的 DStream,而 countByValueAndWindow() 返回的 DStream 则包含窗口中每个值的个数,
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))WordCount第三版:3秒一个批次,窗口12秒,滑步6秒。
object WorldCount { def main(args: Array[String]) { val conf =new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")// batchInterval =3s val ssc =new StreamingContext(conf, Seconds(3)) ssc.checkpoint("./checkpoint")// Create a DStream that will connect tohostname:port, likelocalhost:9999 val lines = ssc.socketTextStream("hadoop0",9000)// Split each line into words val words = lines.flatMap(_.split(" "))//import org.apache.spark.streaming.StreamingContext._//not necessary since Spark1.3 // Count each wordin each batch val pairs = words.map(word => (word,1))//val wordCounts = pairs.reduceByKey((a:Int,b:Int) => (a + b)) // 窗口大小 为12s, 12/3 = 4 滑动步长 6S, 6/3 =2 //valwordCounts =pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(12), Seconds(6))valwordCounts2 =pairs.reduceByKeyAndWindow(_ + _,_ - _ ,Seconds(12), Seconds(6)) //PrintthefirsttenelementsofeachRDDgeneratedinthisDStreamtotheconsolewordCounts2.print()ssc.start() //Startthecomputationssc.awaitTermination() //Waitforthecomputationtoterminate //ssc.stop() } }三、重要操作
3.1 Transform Operation
Transform原语允许DStream上执行任意的RDD-to-RDD函数。即使这些函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API。
该函数每一批次调度一次。
比如下面的例子,在进行单词统计的时候,想要过滤掉spam的信息。
其实也就是对DStream中的RDD应用转换。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { // join data stream with spam information to do data cleaning...
rdd =>
rdd.join(spamInfoRDD).filter(...) }3.2 Join操作
连接操作(leftOuterJoin, rightOuterJoin, fullOuterJoin也可以),可以连接Stream-Stream,windows-stream to windows-stream、stream-dataset
Stream-Stream Joins
val stream1: DStream[String, String] =... val stream2: DStream[String, String] =... val joinedStream = stream1.join(stream2) val windowedStream1 = stream1.window(Seconds(20)) val windowedStream2 = stream2.window(Minutes(1)) val joinedStream = windowedStream1.join(windowedStream2)Stream-dataset joins
val dataset: RDD[String, String] =... val windowedStream = stream.window(Seconds(20))... val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }热门文章
- 2月14日 | Clash Meta每天更新20.6M/S免费节点订阅链接地址
- 2月10日 | Clash Meta每天更新21.5M/S免费节点订阅链接地址
- 1月29日 | Clash Meta每天更新20.4M/S免费节点订阅链接地址
- 开个小型宠物食品加工厂前景怎么样啊 开个小型宠物食品加工厂前景怎么样啊
- 1月16日 | Clash Meta每天更新19.4M/S免费节点订阅链接地址
- 20万左右的四座敞篷跑车有哪些品牌(20万左右的四座敞篷跑车有哪些车型)
- 2月19日 | Clash Meta每天更新19.7M/S免费节点订阅链接地址
- 宠物美容师多少钱一个月知乎招聘工作(宠物美容师价格)
- 动物疫苗和人体疫苗的区别是什么意思啊 动物疫苗和人体疫苗的区别是什么意思啊视频
- Spark系列Spark StreamingDStreams转换